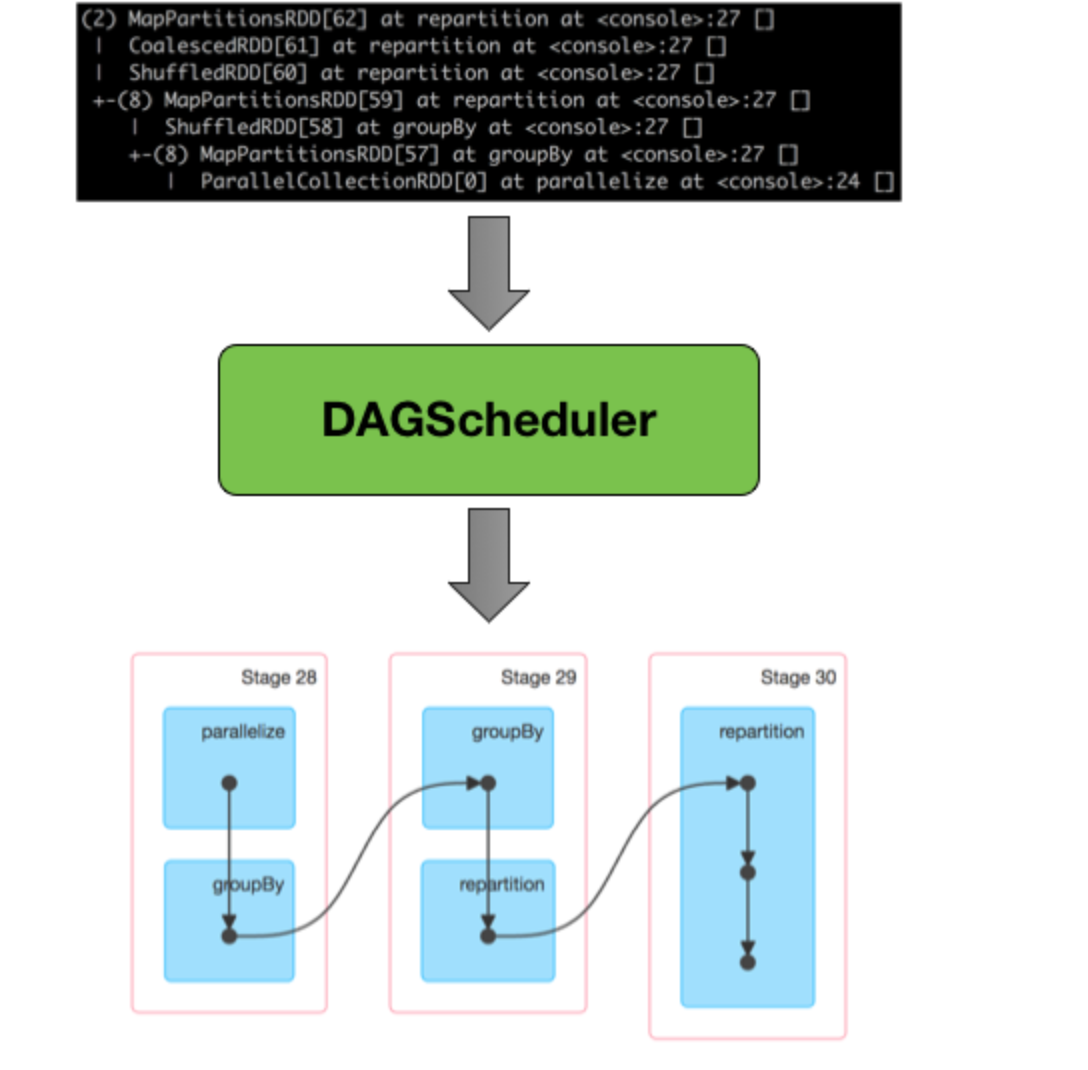
What Is Partitions In Spark. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. Partitioning is nothing but dividing data structure into parts. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. what is spark partitioning ? spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. what is spark partitioning and how does it work? Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. In a distributed system like apache spark, it can be defined as a division of a dataset stored. simply put, partitions in spark are the smaller, manageable chunks of your big data. The main idea behind data partitioning is to optimise your job.
from exocpydfk.blob.core.windows.net
Partitioning is nothing but dividing data structure into parts. what is spark partitioning ? simply put, partitions in spark are the smaller, manageable chunks of your big data. The main idea behind data partitioning is to optimise your job. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. In a distributed system like apache spark, it can be defined as a division of a dataset stored. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. what is spark partitioning and how does it work?
What Is Shuffle Partitions In Spark at Joe Warren blog
What Is Partitions In Spark by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of. simply put, partitions in spark are the smaller, manageable chunks of your big data. in the context of apache spark, it can be defined as a dividing the dataset into multiple parts across the cluster. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on. When spark reads a dataset, be it from hdfs, a local file system, or any other data source, it splits the data into these partitions. what is spark partitioning ? what is spark partitioning and how does it work? Partitioning is nothing but dividing data structure into parts. The main idea behind data partitioning is to optimise your job. Spark partitioning is a way to divide and distribute data into multiple partitions to achieve parallelism and improve performance. In a distributed system like apache spark, it can be defined as a division of a dataset stored. partitioning is the process of dividing a dataset into smaller, more manageable chunks called partitions. by default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of.